Здоровое тело
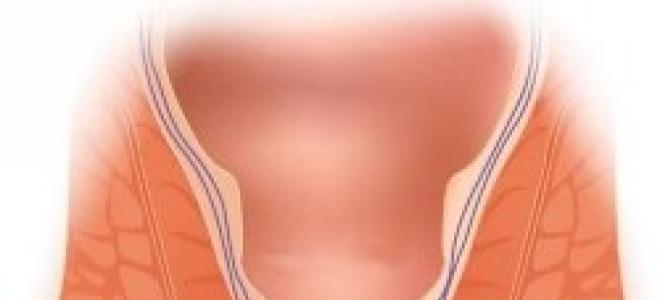
Привычка проводить долгое время в уборной есть у многих людей. Однако не все задумываются, что это может быть вредным для организма. Проктологи советуют...
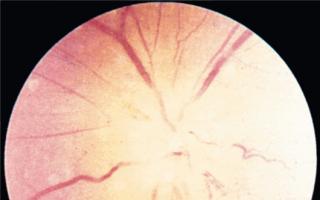
Для осмотра глазного дна (сетчатки, диска зрительного нерва и хориоидеи) пользуются методом офтальмоскопии. Размеры сетчатки сопоставимы с параметрами большой почтовой марки....

Мы живем в воздушном океане, в котором кислород, необходимый для жизни высших организмов, составляет одну пятую часть. Следовательно, люди привыкли к тому, что кислород...

Сифилис - тяжелое инфекционное заболевание, при котором поражаются слизистые оболочки, кожные покровы, разрушается костная ткань и страдает нервная система. Эта венерическая...
Остеопороз очень опасен во время беременности, как для будущей мамы, так и для ребёнка. Можно ли избежать остеопороза принимая препараты кальция и витамин Д? Можно ли защитить...
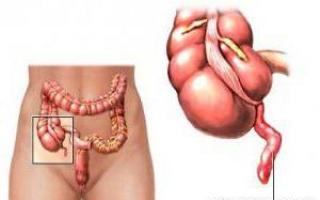
Женскому полу довольно часто приходится сталкиваться с различными недомоганиями. Наиболее популярной причиной обращения пациенток к гинекологу становятся боли внизу живота...
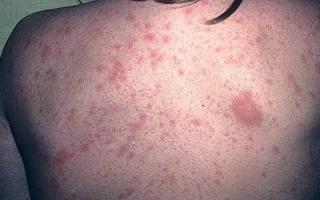
Содержание
Человека иногда застигают врасплох проблемы со здоровьем – больной зуб, покалывание в боку, туман в голове. Некоторые симптомы не всегда являются понятными,...
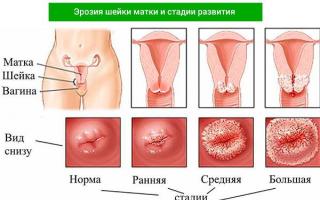
Эрозия – одно из наиболее частых заболеваний репродуктивной системы. От нее не застрахована ни одна женщина. В том числе, встречается эрозия шейки матки у нерожавших.Свернуть...
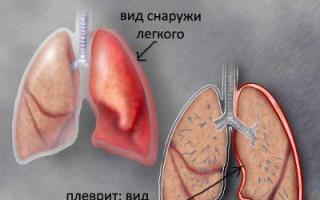
Почти все органы грудной и брюшной полости: легкие, сердце, печень, желчный пузырь, желудок, кишечник и поджелудочная железа получают нервное обеспечение из сегментов грудного...

Похудание (исхудание) - частый признак заболеваний. Резкое похудание называется истощением или кахексией (последний термин чаще применяют для обозначения крайнего истощения)....

Как стареет нервная системаКогда я учился в медицинской школе, нас учили, что ЦНС, центральная нервная система, не может сама исправить нанесенный ей ущерб, такой как травма,...